实践刚学两天的python爬虫
乐乐课堂视频爬取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| import re
from datetime import datetime
from os import error
from urllib import request, error
try:
page = 1
video_url = []
code = 0
file_number = 1
pages = 10
cid = 275359
for a in range(pages):
while True:
resp = request.urlopen("http://www.leleketang.com/let3/knowledge_list.php?cid={}&p={}".format(cid, page))
html = resp.read().decode("utf-8")
video_url = re.findall("http://.+.mp4", html)
if len(video_url) != 0:
break
else:
video_url = []
print(video_url)
print("共有{}个视频正在下载".format(len(video_url)))
for img in video_url:
file_name = "/Users/yejizhi/Desktop/video/{}.mp4".format(file_number)
request.urlretrieve(img, file_name)
file_number = file_number+1
print("{}个视频已下载完成".format(len(video_url)))
video_url = []
page = page+1
except error.HTTPError as e:
print("error:{}".format(e.code))
|
流程图表示:
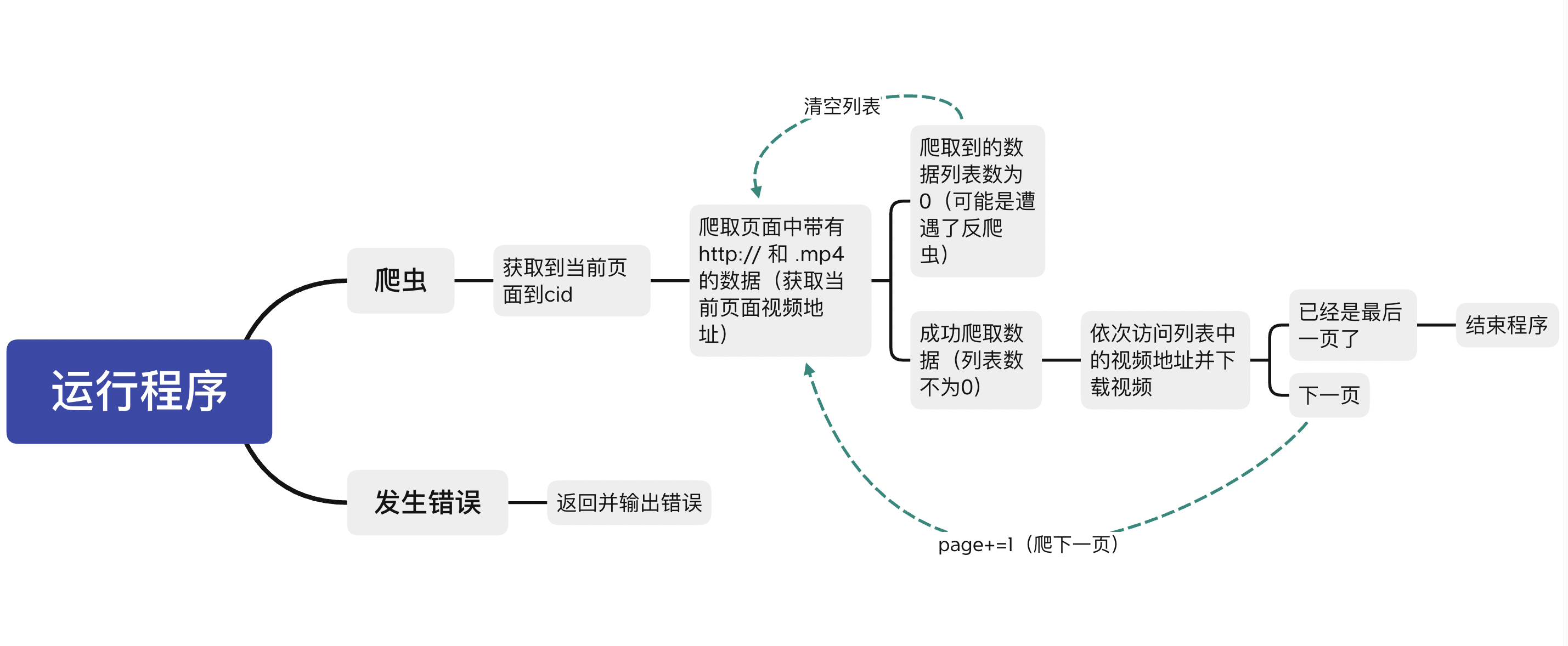
cid指的是服务器发送来的数据链接尾巴的一个变量
在网页中打开开发者工具Network可以获取到它
例如https://www.leleketang.com/let3/knowledge_list.php?cid=252843&p=1
尾巴的252843就是cid的值,每个年级每本教材都有一个对应的cid,可以直接替换
p为当前页码
在这个网页的源代码中可以找到mp4格式视频地址
所以代码中的cid和pages需要手动修改
pages指的是一共有多少页
有时间我再完善代码让它可以自动获取总页数
奥运会运动员信息爬取
这是我之前学习爬虫时的一个课堂作业
源代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| import json
from urllib import request
import time,random
import csv
all_athlete = []
for page in range(1, 29):
url = "https://gw.m.163.com/olympic/2020/athleteList/chinaAllItem_{}.json".format(page)
resp = request.urlopen(url)
data = resp.read().decode("utf-8")
data_obj = json.loads(data)
athleteLst = data_obj["data"]["ul"]
for athlete in athleteLst:
d_url = "https://gw.m.163.com/olympic/2020/athlete/{}.json".format(athlete["athleteId"])
d_resp = request.urlopen(d_url)
d_data = json.loads(d_resp.read().decode("utf-8"))
athlete_info = d_data["data"]["athleteInfo"]
node = {}
node["name"] = athlete["athleteName"]
info_lst = athlete_info.split("#")
for info_item in info_lst:
item_data = info_item.split(":")
if item_data[0] == "姓名":
node["sex"] = item_data[1]
elif item_data[0] == "生日":
node["birthday"] = item_data[1]
elif item_data[0] == "项目":
node["item"] = item_data[1]
all_athlete.append(node)
print("=", end="", flush=True)
time.sleep(random.randint(1,3))
with open("/Users/yejizhi/Desktop/athlete.csv", "w", encoding = "utf-8", newline = "") as f:
field_name = ["name","sex","birthday","item"]
writer = csv.DictWriter(f, fieldnames = field_name)
for athlete in all_athlete:
writer.writerow(athlete)
print("爬虫结束")
|
原理是从云端发送来的json数据使用python爬虫下来再进行字符串分割保留需要的内容
写进csv表格文件里
athlete
| 马龙 |
|
1988.10.20 |
乒乓球 |
| 朱婷 |
|
1994.11.29 |
排球 |
| 苏炳添 |
|
1989.8.29 |
田径 |
| 谌龙 |
|
1989.1.18 |
羽毛球 |
| 张常宁 |
|
1995.11.06 |
排球 |
| 刘诗雯 |
|
1991.4.12 |
乒乓球 |
| 范忆琳 |
|
1999.11.11 |
竞技体操 |
| 吕小军 |
|
1984.7.27 |
举重 |
| 谢文骏 |
|
1990.7.11 |
110米栏 |
| 黄常洲 |
|
1994.8.20 |
跳远 |
| 高兴龙 |
|
1994.3.12 |
跳远 |
| 杜凯琹 |
|
1996.11.27 |
乒乓球 |
| 王嘉男 |
|
1996.8.27 |
跳远 |
| 张耀广 |
|
1993.6.21 |
跳远 |
| 苏慧音 |
|
1998.4.13 |
乒乓球 |
| 朱亚明 |
|
1994.5.4 |
三级跳远 |
| 李皓晴 |
|
1992.11.24 |
乒乓球 |
| 吴瑞庭 |
|
1995.11.29 |
三级跳远 |
| 王宇 |
|
1991.8.18 |
跳高 |
| 郑怡静 |
|
1992.2.15 |
乒乓球 |
| 黄博凯 |
|
1996.9.26 |
撑杆跳高 |
| 陈思羽 |
|
1993.8.1 |
乒乓球 |
| 蔡泽林 |
|
1991.4.11 |
竞走 |
| 郑先知 |
|
1993.4.18 |
乒乓球 |
| 罗亚东 |
|
1992.1.15 |
竞走 |
| 吕秀芝 |
|
1993.10.26 |
竞走 |
| …… |
|
…… |
…… |